In the previous article (opens new window), we've learnt the physical and logical structure of PostgreSQL, how data is read and written.
PostgreSQL is a client/server relational database. As is typical of client/server architecture, the client and the server can be on different hosts and communicate over a TCP/IP network connection.
In the simplest term a PostgreSQL service has 2 processes;
- Client-side process: These are the applications that users use to interact with the database. It generally has a simple UI and is used to communicate between the user and the database generally through APIs
- Server-side process: This is the “Postgres” application that manages connections, operations, and static & dynamic assets.
# Client-side Process
When the user runs queries on PostgreSQL, the client application can connected to the PostgreSQL server (Postmaster Process) and submit queries through one of many Database Client API supported by PostgreSQL like JDBC, ODBC, Perl DBD etc. that helps to provide client-side libraries.
# Server-side Process
The server-side processes consists of the following processes;
- Postgres server process (Postmaster Process) which is the parent of all processes related to a database cluster management.
- Backend process that handle all queries and statements issued by a connected client.
- Background worker process, it can perform any processing implemented by users.
# Postgres Server Process
When the PostgreSQL server is started with the pg_ctl utility, the postgres server process is initiated. It allocates
a shared memory area in memory, starts various background processes and waits for connection requests from the clients.
Whenever a connection request is received from a client, it starts (“forks”) a backend process which handles all queries issued by the connected client.
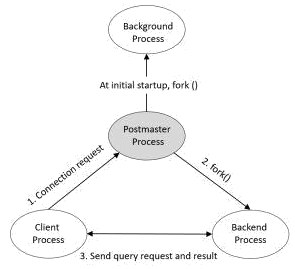
From that point on, the client and the new server process communicate without intervention by the original postgres process. Thus, the postges server process is always running, waiting for client connections, whereas client and associated server processes come and go.
Some of the processes started by the postgres server process include;

A postgres server process listens to one network port, the default port is 5432. Although more than one PostgreSQL server can be run on the same host, each server should listen on a different port number.
PostgreSQL has not implemented a native connection pooling feature. If many clients frequently repeat the connection and disconnection process, it increases both costs of establishing connections and of creating backend processes. Such circumstance has a negative effect on the performance of database server. To deal with such a case, a pooling middleware (pgbouncer or pgpool-II) is usually used.
# Memory architecture
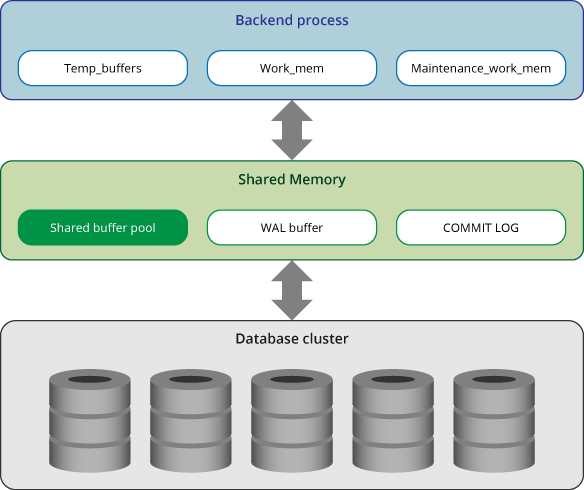
Memory in PostgreSQL can be classified into two categories;
- Local Memory area - Each backend process allocates a local memory area for query processing.
- Shared memory area- Used by all processes of a PostgreSQL server after being allocated during server startup.
# Closing thoughts
In this chapter, we looked at the different processes of a PostgreSQL server and how they are initiated. We also touched briefly on the two categories of memory.
